R&D on integrated big data processing manners based on new theory and implementation. They include mathematically redesigning machine learning systems and implementing high accurate and safe A.I. In addition, they achieve high confidential big data processing, through statistically analyzing the results generated by the systems.
Introduction and Background
In most science areas, which include DNA & molecule designs in micron level and earth environment sciences in macro level, it is so important to extract meaningful information from big data, which is superficially useless data with huge size. The extraction techniques are called data mining. Data mining is so costly that it is difficult to process it in traditional ways. To achieve much more efficient and accurate data mining and result in innovative science technologies, we have to propose new approaches based on mathematical theorems in algorithms and execution styles.
Division of Super Distributed Intelligent Systems, which is the previous division, especially focuses attention to medical and bio-systems, and has developed next generation data mining softwares together with researchers in artificial intelligence and statistics areas. In the process of that, we have found that we have to not only enhance parallelization/distribution and propose new approaches based on mathematical theorems to achieve new innovative technologies. In Division of Digital Transformation, we will improve the results of the previous division, and develop new big data processing manners based on performance and accuracy issues that the results have exposed. For example, we will continuingly enhance execution efficiency in the low level that is related with programming languages, parallel/distributed algorithms, and network protocols. In addition, we will design new deep learning manners based on adjusting their super-parameters based on combinatory theorem. Eventually, we will apply these techniques and models to several areas such as image processing, power systems, machine learning, robot systems, software engineering tools and so on, including data mining.
Research Hierarchy
We address the issues of big data processing in three hierarchical levels, “applications”, “fundamentals, and “theories” as follows:
1. Applications
In this level, members who are specialists of each applications investigate issues of the applications based on their expertise, propose approaches to solve the issues, and check validity of results given by the solution. In the process, they give new models based on characteristics of the applications, and develop systems implementing the models. The results given by the systems are validated in mathematical methods.
2. Fundamentals
In this level, members directly improve performance of fundamental techniques such as A.I. and machine learning, and propose new approaches of them. The improvement of performance includes network performance in distributed systems and sensor networks, and learning performance of A.I. through parallel and distributed techniques. The new approaches include improvements of parallelism in instruction level on GPU, improvement of accuracy of existing machine learning, and development of new machine learning model based on biological systems. The fundamental techniques and systems developed in the level are validated in mathematical methods.
3. Theories
In this level, members give proofs of techniques with black box parts such as deep learning and machine learning. Furthermore, through knowledges obtained in the process, they propose new methods or system models.
Research Topics
We currently have two main projects as follows:
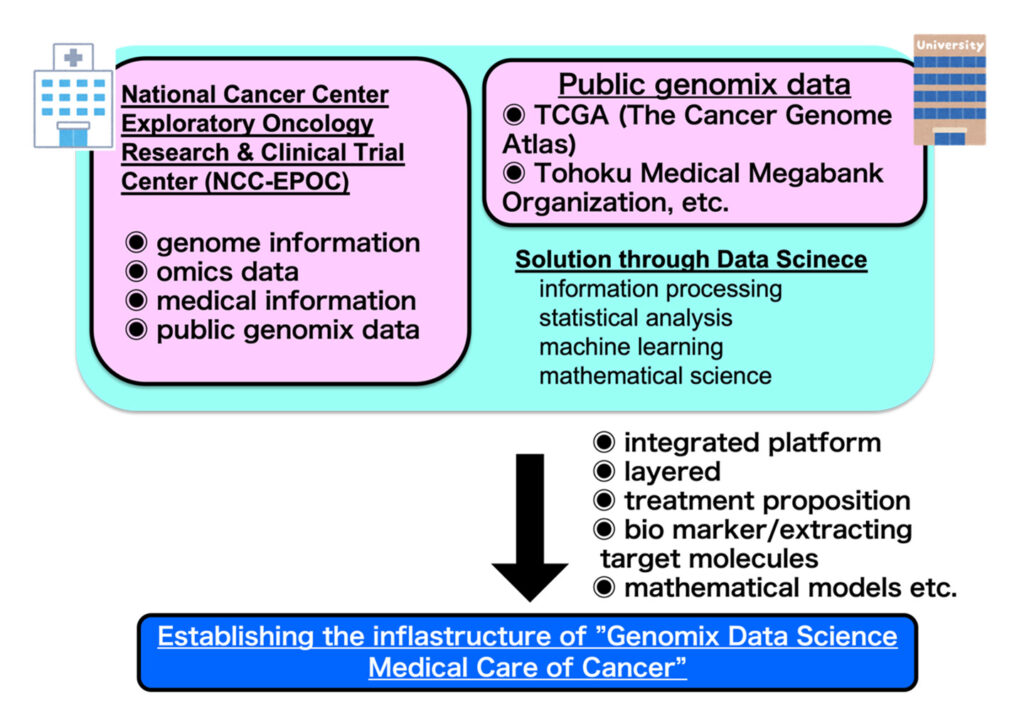
1. Genomix Data Science Medical Care of Cancer
It is a project that is advanced with National Cancer Center Exploratory Oncology Research & Clinical Trial Center (NCC-EPOC) as a cooperative research (Fig. 1). In this project, the purposes in the applicative level are cancer prevention, lengthening the time of a healthy life, improvement of quality of life and rehabilitation. Also, we are developing methods special to each applicative level purpose through fusing data sciences such as mathematical statistics, machine learning, information processing and statistical analysis, and cancer biological experiments.
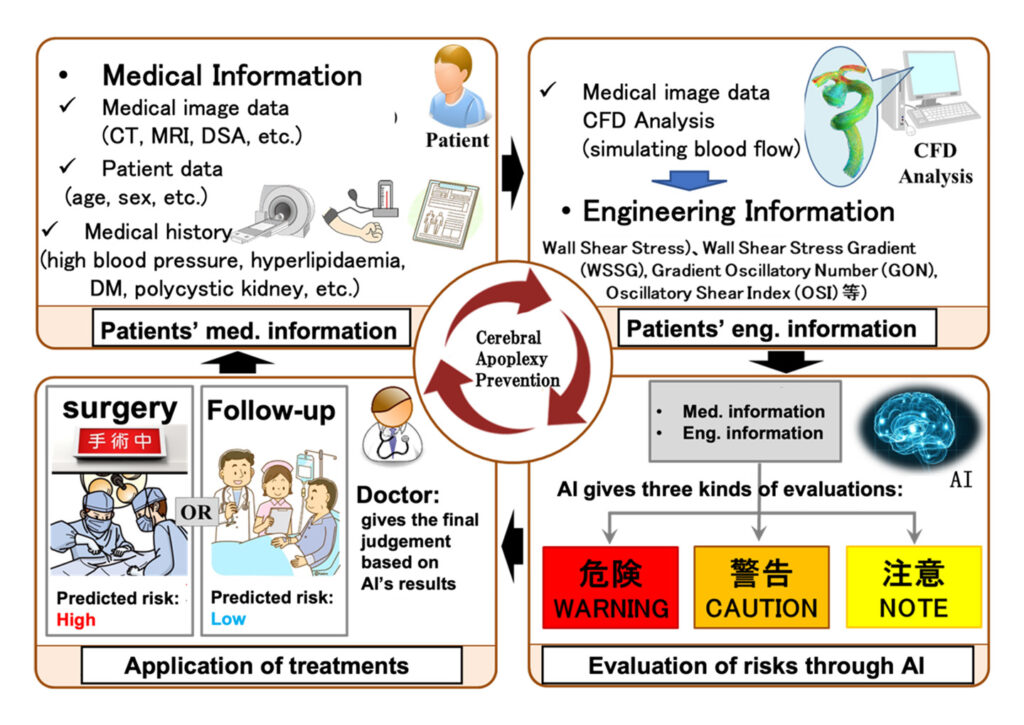
2. Implementation and Practical Realization of Cerebral Apoplexy Prevention by AI
We are developing the system that enables AI to support a doctor medically examining or treating patients of cerebral apoplexy using medical big data and engineering big data. This project started as one of NEDO projects, implementing two kinds of A.I.s, which were A.I. α based on just medical information and A.I. β based on both of medical information and engineering information.